本文共 7914 字,大约阅读时间需要 26 分钟。
Google 2016.10.06
官方 Blog 链接:https://research.googleblog.com/2016/10/graph-powered-machine-learning-at-google.html
今天讲的是一个基于 streaming approximation 的大规模分布式半监督学习框架,出自 Google 。
摘要:众所周知,传统的 graph-based 半监督学习方法不适合处理大批量数据和大型标签场景,因为其计算量和他们的 边 |E| 和 直接标签 m 的个数是线性关系。为了处理大型标签尺度问题,最近的工作提出了 sketch-based methods 来预测每一个节点的标签分布,故而将空间复杂度由 O(m) 降到了 O(log m),在一定的条件下。
本文提出一种 新颖的 streaming graph-based SSL approximation 的方法有效的抓住了标签分布的稀疏性(the sparisity),进一步的将空间复杂度降到了 O(1). 与此同时,本文提出一种分布式版本的算法可以处理大批量数据的情况。在实际世界的数据集中的实验,证明所提出的方法比现有方法可以达到明显的内存降低。最后,本文提出一种鲁邦的利用半监督深度学习框架的 graph augmentation strategy,并且在自然语言应用上取得了较好的半监督学习效果。
引言:SSL 是利用少量有标签数据和海量无标签数据去训练一个预测系统(prediction systems)。其研究意义就在于,现有的标注总是少量的,而且标注工作是枯燥耗时的,而无标签数据又是海量的,如何利用有限的有标签数据结合海量无标签数据,进一步的提升现有模型的性能,是一个值得关注的课题。
关于不同 SSL methods 的局限性,主要体现在:昂贵的计算代价! 比如,transductive SVM 和 Graph-based SSL 算法是 SSL 算法中比较出名的一个子类。这些方法的核心 idea 就是构建和平滑一个 graph,利用 点 和 边 去链接他们之间的关系。边权(edge weights)是根据节点之间的相似性得到的。基于标签传递(label propagation)的 Graph-based methods 利用已有的种子节点,通过 graph 去传递其标签信息。这些方法通常收敛的很快,并且他们的时间和空间复杂度和边的个数以及 label 的个数呈线性关系。
但是,有些场景所涉及到的样本数量 和 label 个数真的是非常巨大,常规的基于 graph 的 SSL 方法无法处理。通常,单独的节点用稀疏的标签分布来进行初始化,但是随着迭代次数的增加,他们将变得 dense。Talukdar and Cohen 最近提出一种方法【1】试图克服 label scale problem ,通过一个 Count-Min Sketch 的方法来预测每一个 node 的 label 和他们的 score 。这使得内存复杂度变得非常低。但是,在实际世界的应用中, actual label k 的个数和每一个节点的连接实际上是 sparse 的,尽管总的 label space 是非常 huge 的,也就是说 K 是远小于 m 的。很明显,在实际应用中,考虑到label 的稀疏性可以显著的降低复杂度。
Contributions:
1. 本文提出一种新的 graph propagation algorithm 进行 general purpose SSL 。
2. 该算法可以处理有大量 label 的情况。其核心是,利用一种 approximation 有效的抓住了 标签分布的稀疏性,确保算法可以准确的传递标签。
3. 提出 并行化处理版本的算法,可以很好的处理 large graph sizes.
4. 提出一种 有效的线性时间 构图策略,可以有效的结合多种信号,可以动态的从 sparse 到 dense representation。
5. 特别的,graphs ,节点表示文本信息,仅仅利用 原始文本 和 顶尖的 DL 技术,可能会鲁邦的学习到和这些节点联系的 latent semantic embeddings 。
用这种 embedding 的方式增强原始 graph,然后用 graph SSL 产生了明显的提升。
Graph-based Semi-Supervised Learning :
Preliminary : 目标是产生一个 soft assignment of labels to each node in a graph G=(V,E,W)。
Graph SSL Optimization :
通过最小化下列的目标函数来学习一个 label distribution $Y^^$ :
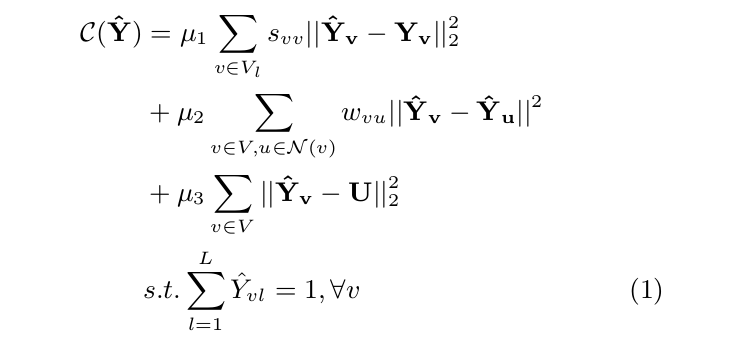
其中,N(v) 代表 节点 v 的近邻节点,U 是所有label 的先验分布。
以上目标函数建模了:
(1). the label distribution should be close to the gold label assignment for all the seeds ;
(2). the label distribution of a pair of neighbors should be similar measured of a pair of neighbors should be similar measured by their affinity score in the edge weight matrix ;
(3). the label distribution should be close to the prior U, which is a uniform distribution.
公式 1 的优化可以通过 Jacobi iterative algorithm,这个算法定义了第 (i+1) th iteration 的近似解,给定第 i 次迭代的 solution 为:
其中, i 是迭代的索引,$U_l = \frac{1}{m}$ 是 label l 的均匀分布。
我们将这种优化 公式 1 的方法暂且称为:EXPANDER
DIST-EXPANDER: Scaling To Large Data .
为了处理 huge graph 的情况,我们提出了多机并行的算法版本。
Streaming Algorithm for Scaling To Large Label Spaces :
Talukdar et al. 采用一种 Count-Min Sketch approximation 来存储每一个节点的整个标签分布,特别是对于大型 label 集合,因为 每一个节点的标签分布通常都很 sparse,仅仅 top ranking ones 是有用的。此外,the Count-Min Sketech 可能对于 top ranking labels 是有害的。
与此对应,我们的工作并不是试图执行 sparsity,而是focus 在 用一个 streaming approximation 的方式在 SSL 的过程中,有效的存贮 和 更新 label distribution 。
EXPANDER-S Methods:
我们提出一种 streaming sparsity approximation algorithm 来进行 SSL 达到了 constant space complexity,并且节省了大量的内存空间。
这个方法可以有效的以一种 streaming fashion的方式,从近邻中处理信息;并且 记录了 每一个节点 top ranking labels 的 sparse set,然后预测剩下的估计。总的来说,这种方法类似于从数据流中寻找出常见的项目(frequent items), 这些 items 是 label;streams 是从紧邻得到的 messages。我们的 Pregel-based approach (算法1)提供了一个自然的框架来执行信息流的想法。
算法 1 流程如下:

Preliminary :
Manku et al 提出了一种算法在 data streams 中,来计算超过用户设定的频率次数,而其他人则利用这种算法去处理 NLP 中出现的大数据的问题。主题的想法是:
a data stream containing N elements is split into multipule epochs with $\frac{1}{\epsilon}$ elements in each epoch.
所以,总共有 $\epsilon N$ 个 epochs,每一个这样的 epoch 有一个从 1 开始的 ID。该算法处理顺序的从每一个 epoch 处理 elements,然后保持一个三元组形式的列表 $ (e, f, \delta) $, e 是一个 item, f 是其 reported frequency, $\delta$ 是频率预测的最大误差。在当前的 epoch t,当一个项目 e 到来时,就增加了频率统计 f,如果该 item e 包含在 tuples 的列表当中。否则,就会创建一个新的 tuple (e, l, t-1) 。然后,在一个 epoch 后,该算法滤掉最大频率较小的那些 items。特别的,如果 epoch t 结束了,那么算法就会删掉所有满足条件($f + \delta <= t $)的 tuples。这就确保了 rare items 不会被保留到最后。
Neighbor label distribution as weighted streams :
直观的讲,我们的设定中,每一个 item 是一个 label,每一个 neighbor 是一个 epoch。对于一个给定的 node v,Neighbors 将 label probability streams 传递给节点 v,每一个 Neighbor $v \in N(v)$ 是一个 epoch,其大小为:$|N(v)|$ 。我们保存了一个 tuple 的 list $l, f, \delta$ ,其中 l 是labels index, f 是 weighted probability value,$\delta$ 是加权概率估计的最大误差。对于当前的 Neighbor $u_t$ (也就是说,v 的 第 t 个近邻),节点 v 接受到了带有权重 $w_{v u_t}$ label distribution $Y_{u_t l}$。这个算法然后做两件事情:
1. 如果 label l 当前已经在 tuple list 当中,那么就会增加 probability value f ,通过 add w * Y ;
2. 否则,就会创建一个新的 tuple list 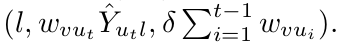 ,
,
其中的 $\delta$ 作为 probability threshold. 这个值在一个 item frequency streams 很自然的是 1 ,我们的是一个概率权重。
此外,每一个 epoch t,Neighbor $u_t$ 通过 edge weight $w_{vu_t}$ 进行加权。然后,在我们收到第 t 个 Neighbor 之后,我们过滤掉最大概率小的那些 label 。如果 满足 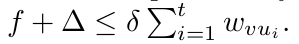 ,我们就将 label l 删掉。
,我们就将 label l 删掉。
Memory-bounded update:
给定 streaming sparsity algorithm,我们可以确保 没有 low weighted-probability labels 会保留下来 (在收到所有 Neighbors 的 messages)。然而,在许多案例中,我们需要将 保留的labels 的个数限制在 k 个,也就是说,基于其概率保留其 top-k 个。在这种情况下,对于一个节点 v 来说,其每一个 Neighbor u 仅仅包含一个 top-k labels。此外,我们利用设定的阈值 来计算保留的labels 的平均概率。然后我们采用之前的 streaming sparsity algorithm 算法。唯一的不同在于,当 label $l$ 不在当前的 tuple list 当中,则会新建一个新的 tuple ,形如:![]() 。直观的来讲,并非选择一个全局的 threshold,我们基于之前看到的Neighbors 变换不同的阈值。在每一个 epoch,在从当前 (t-th neighbor) 接收到信号后,我们扫描当前的 tuple list。对于每一个 tuple $(l, f, \delta)$,如果 label $l$ 不在当前第 t 个Neighbor 的 top-k label list 当中,我们通过 adding $\delta_{u_t}$ 增加其概率值 f 。最后,在接收到所有的 Neighbors 信息之后,我们 ranking 所有剩下的 tuples 基于 tuple $(l, f, \delta)$ 当中的值 $f + \delta$。这个值代表最大加权的概率预测。然后我们选择 top-k labels,然后只记录当前 node v 的概率。
。直观的来讲,并非选择一个全局的 threshold,我们基于之前看到的Neighbors 变换不同的阈值。在每一个 epoch,在从当前 (t-th neighbor) 接收到信号后,我们扫描当前的 tuple list。对于每一个 tuple $(l, f, \delta)$,如果 label $l$ 不在当前第 t 个Neighbor 的 top-k label list 当中,我们通过 adding $\delta_{u_t}$ 增加其概率值 f 。最后,在接收到所有的 Neighbors 信息之后,我们 ranking 所有剩下的 tuples 基于 tuple $(l, f, \delta)$ 当中的值 $f + \delta$。这个值代表最大加权的概率预测。然后我们选择 top-k labels,然后只记录当前 node v 的概率。
接下来,作者给出了一个 lemma :
Lemma 1 :
对于任意的 node $v \in V$,用 y 表示 un-normalization true label weights,y^ 是通过 streaming sparsity approximation version of EXPANDER algorithm 得到的估计。用 N 表示在 aggregation 之前,从 u 的所有 Neighbors 得到的 labels entries 的总数,$d = |N(u)|$ 是node u 的degree,k 是 y^ 当中保留的 entries 的固定个数,其中,$N <= k*d$,然后:
(1). 对于所有的 labels $l$,所提出的稀疏估计误差被限制在: 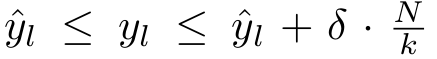
(2). 该算法的每一个 node 的空间要求为:$O(k) = O(1)$ 。
Graph Construction :
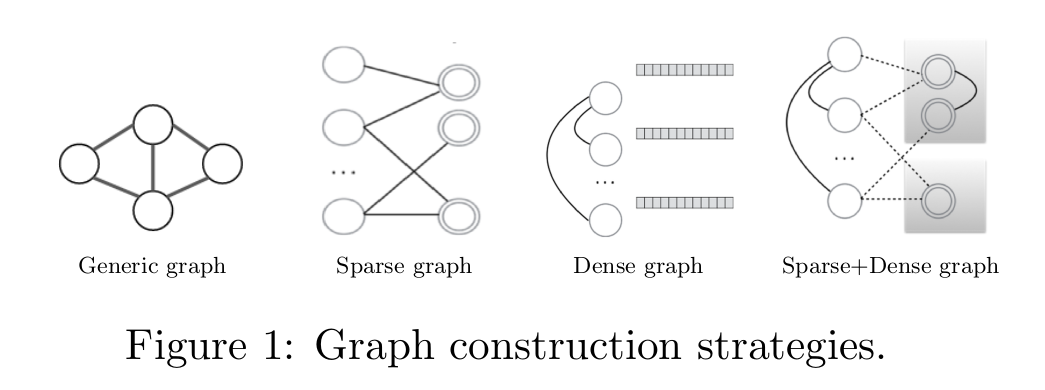
Graph-based SSL algorithm 的主要成分就是 输入图 本身。图的构建对于后续输出的结果有很大的影响。基于 edge link information 和 vertex representation,有许多种方法来构建 graph:
(a)Generic graphs 代表观测到的Neighborhood ,或者 link information connecting vertices ;
(b)对于每一个 vertex 从 稀疏特征表示 构建的 graphs;
(c)对于每一个 vertex 从dense representations 构建的 graphs;
(d)用上述混合的方式构建的 augmented graphs
图 1 展示了各种图结构的示意图。我们集中在 (b)(c)and(d)上,因为其在NLP 上有更加广泛的应用。
Sparse instance-feature graphs (b)通常被用作大部分 SSL 任务的输入。接下来,我们提出一种方法能够自动的构建 (c)这种类型的图,并且基于此,构建出增强的 graph (d)可以抓住 sparse 和 dense per-vertex 的特性。
Graph Augmentation with Dense Semantic Representation :
本文提出一种更加 robust 的策略来构建 graph augmentation ,这个遵循两个步骤:
First,we learn a dense vector representation that captures the underlying semantics associated with each (text) node.
(我们学习一个 dense vector 表达,能够抓住每一个节点的潜在语义)
我们借助最近的 Deep Learning 的方法有效的学习单词 和 段落语义 在一个 dense 的低维空间。
我们采用 Mikolov 等人的工作 来从大型的 dataset 中学习到 words (or phrase)连续的特征表示。这种方法将 文本资料库 作为输入,学习到一个向量表示来表示每一个单词或者短语。我们 continuous skip-gam model 结合 hierarchical softmax layer,句子当中的每一个单词被用作线性分类器的输入,试图学习到 同一句话当中另一个单词的最大分类。关于这个训练过程和网络结构,可以参考【2】。
【2】 Efficient estimation of word representations in vector space. ICLR 2013
此外,这些 models 可以有效的并行处理,利用分布式训练框架可以处理大型的 datasets 。
Next,for each node $v = w_1w_2 ... w_n$,我们从 node text 当中得到的 words 中,得到对应的 embedding $v_{emb}$,并且查询到 pre-trained vectors :
基于此,我们利用 embedding vectors 的 nodes pairs 计算相似性函数,其中 $sim_{emb} (u, v) = u_{emb} * v_{emb}$ 。我们过滤掉 node pairs (with low similarity values),对于剩下的 pairs,在原始的 graph G 中添加一个 edge 。
但是不幸的是,上述策略需要 $O(|V|^2)$ 相似性计算代价,这在实际应用当中是不可能的。为了处理这个挑战,我们借助 locallity sensitive hashing (LSH),一种随机的映射方法 用来有效的估计 nearest Neighbor lookups ,当 data size 和 dimensionality is large 。我们利用节点 embedding vectors $v_{emb}$ ,并且执行了 LSH 有效的降低了不需要的 pairwise 的计算,将会产生低相似性的值。
转载地址:http://ojnbx.baihongyu.com/